【八股文】找实习自用八股文笔记(语义分割)(未完成)

上图为计算机视觉的三大任务,目标检测,语义分割和实例分割。
FCN
FCN的目的是对图片进行语义分割,即对每一个像素进行分类,输出该像素是否是物体上的像素。
主要思想
- 不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
- 增大数据尺寸的转置卷积层。能够输出精细的结果。
- 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
FCN与CNN的区别在于FCN把CNN最后的全连接层换成卷积层,输出语义分割结果。
转置卷积
卷积层可表示为$Ax = b$,A为卷积的托普利兹矩阵。
$A^Tb = x$即为转置卷积。
跳跃结构
网络中存在若干pooling层,将该层输出进行转置卷积上采样,与前一个pooling层的输出逐像素相加。如下图所示。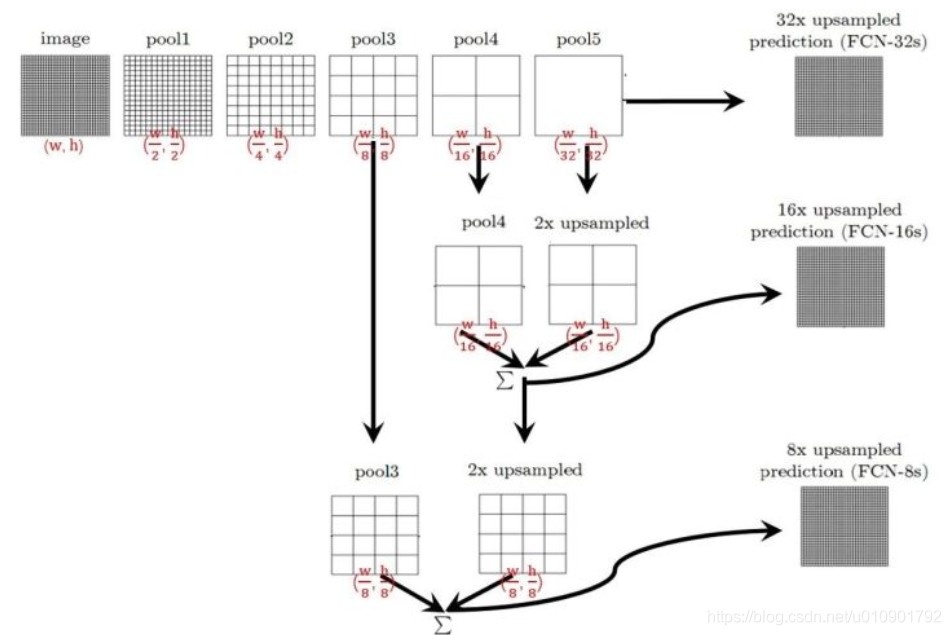
将最后三个pooling层的输出按此方法拼接,最终的转置卷积步长为8,即8倍上采样才能让输出与输出图片尺寸相同。
网络结构
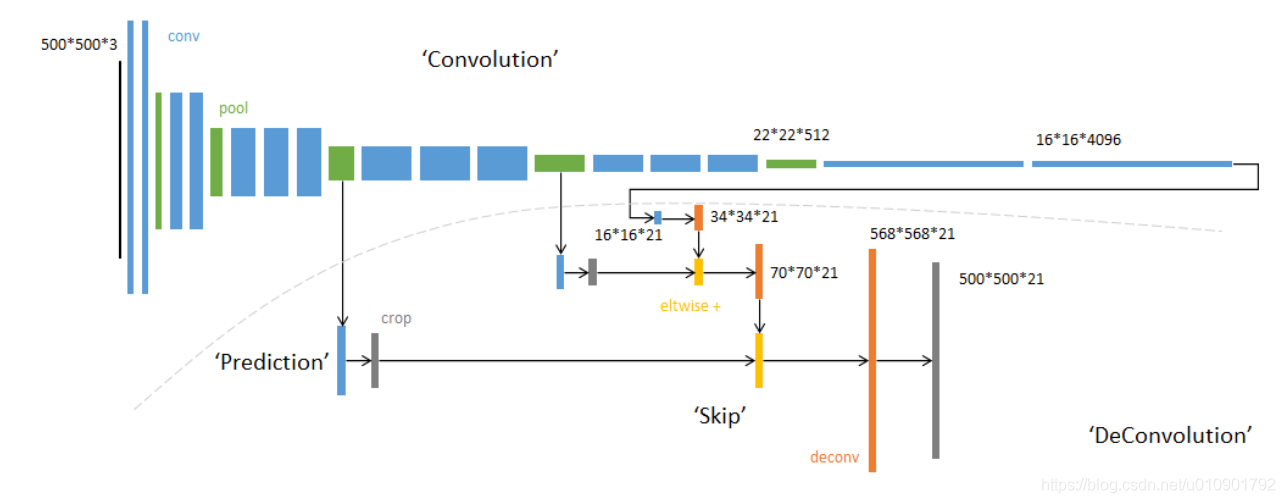
- 蓝色:卷积层
- 绿色:Max Pooling层
- 黄色: 求和运算, 使用逐数据相加,较浅的结果更为精细,较深的结果更为鲁棒。
- 灰色: 裁剪, 在融合之前,使用裁剪层统一两者大小, 最后裁剪成和输入相同尺寸输出
- 橙色:转置卷积,最后一个橙色转置卷积步长为8。
- 对于不同尺寸的输入图像,各层数据的尺寸(height,width)相应变化,深度(channel)不变
- 最终的输出通道数为21,因为PASCAL数据集共20类,加上背景类为21。
所以损失函数为输出的21通道对每个像素位置使用softmax得到分类结果。
Mask-RCNN
网络结构
Mask R-CNN是一个非常灵活的框架,可以增加不同的分支完成不同的任务,可以完成目标分类、目标检测、语义分割、实例分割、人体姿势识别等多种任务。
Mask-RCNN 大体框架还是 Faster-RCNN 的框架,在RPN后接Fast-RCNN来预测种类和bbox回归,就是Faster-RCNN。而RPN后接另一个分支即为Mask-RCNN。其中RPN的作用不变,都是proposal可能会出现物体的regions。
Mask-RCNN部分为一个全卷积网络的分支,对每个RoI预测了逐像素的分割遮罩,以说明给定像素是否是目标的一部分。当像素属于目标的所有位置上时标识为1,其它位置标识为 0。示意图如下: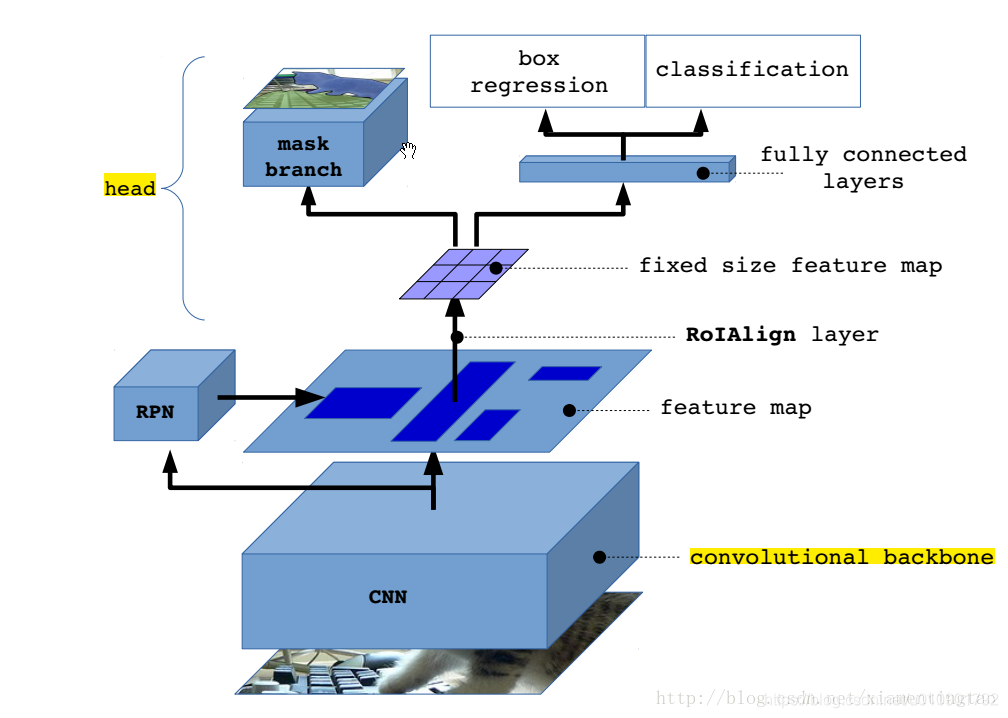
与Faster-RCNN不同点:
- ROI Pooling改为ROI Align
- 提取特征的网络由VGG改为Resnet
- 添加并列的FCN(Mask部分)
ROIAlign
ROI Pooling经历了两个量化的过程:
- 从RPN预测的ROI proposal到feature map的映射过程。若映射的结果不在feature map的整数位上,比如x/16不是整数,则ROI pooling需要四舍五入至整数。
- 在feature map划分成k*k的区域,在分区域过程也需取整。对每个区域使用max pooling。
这两个过程都损失了ROI区域内的特征。
而做分割是像素级别的,损失这些特征就无法很好地预测。
ROIAlign取消量化的方法是使用双线性插值计算非整数坐标部分的特征。
若ROI proposal映射到feature map时,不进行四舍五入取整而是保留小数区域。如下图所示:

并与ROI pooling相同,若需要输出kk个数,则平均分为面积相等的k\k个区域。在分区域时也不进行取整。如下图所示:
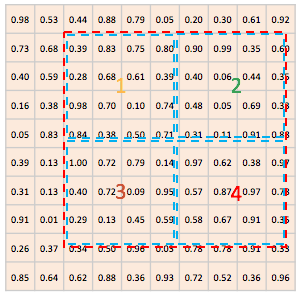
之后对每个区域进行若干点采样,若采样点数量为4,则如下图所示,对每个点使用双线性插值的方法计算采样点处的特征值。最后再对每个区域内的采样点做max pooling即可输出k*k个值。

FPN
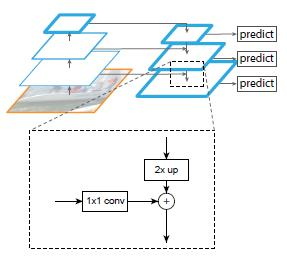
在RPN中使用FPN
在Faster—RCNN中,RPN负责预测可能出现物体的ROI,方法是对feature map中每一个位置假设存在多个尺寸的anchor box。但使用FPN后,可假设每个输出中的像素含有一个尺寸的anchor box,而不必假设每个输出有多个尺寸的anchor box。
在Fast-RCNN中使用FPN
Fast-RCNN的ROIpooling之前,需要提取特征为feature map,现在可以根据FPN的不同尺度的feature map作为后续计算。若ROI较大,则使用更深的feature map输入ROI pooling,否则就输入浅层feature map。根据以下公式确定使用哪一个feature map进行后续计算:
224为imageNet的图片尺寸。k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值应该会做取整处理,防止结果不是整数。
整个Mask-RCNN的结构示意图如下:
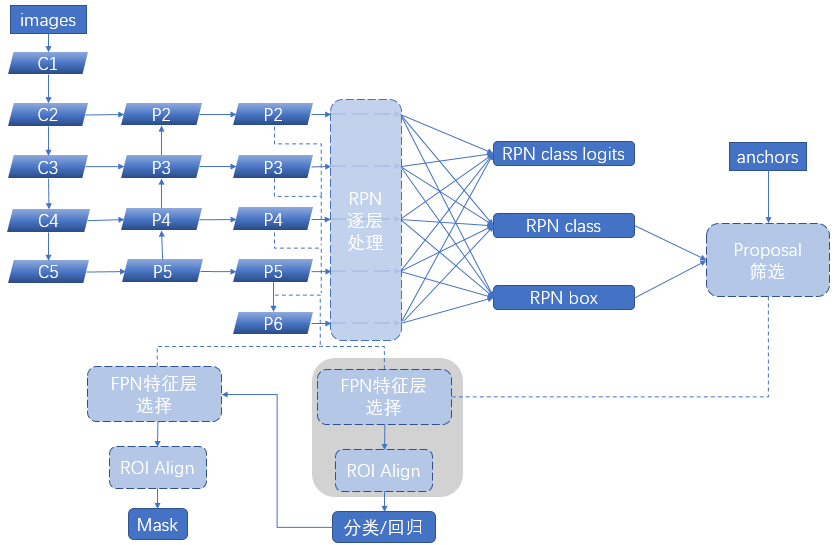
其中FPN作为特征提取的主干网络,输出多个尺度的feature map,RPN使用这些feature map,在每个位置使用同一尺寸的anchor box,预测可能出现物体的ROI。根据ROI的大小,确定用来计算的FPN的feature map进行后续的ROI Align和输出。
FPN与U-Net的区别
- FPN用来detection;U-Net用来segmentation。
- FPN的“放大”部分是直接插值放大的,没有学习参数;U-Net“放大”部分就是需要使用反卷积上采样,需要学习参数。
- FPN及其大多数改进都是把原Feature Map和FPN的Feature Map做加法;U-Net及其大多数改进都是把原Feature Map和Decoder的Feature Map做Concatiantion,再做1x1卷积。
- FPN对每一个融合的层都做detection;U-Net 只在最后一层做segmentation的pixel预测。
损失函数
前两项与Faster-RCNN相同,第三项$L_{mask}$为Faster-RCNN部分预测的ROI中,FCN对这些ROI区域的每个像素的分类结果。而FCN部分只考虑对Faster-RCNN预测出的分类结果做像素分类,而不像FCN需要在分割的同时进行像素分类。
参考
https://blog.csdn.net/qq_36269513/article/details/80420363
https://blog.csdn.net/u010901792/article/details/100044200
https://zhuanlan.zhihu.com/p/44741620
https://www.zhihu.com/question/351279839
https://blog.csdn.net/qq_33547191/article/details/88695405
https://www.cnblogs.com/hellcat/p/9814975.html