【机器学习】C++手撸一个BP神经网络(支持minibatch,Adam优化)

每个函数以及变量的含义已经写在注释中。
使用数据:点击下载
测试结果:(第一列为训练集acc,第二列为测试集acc,每行的行数为神经网络层数,每层20个神经元)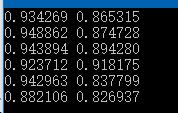
测试的时候层数不能太深,容易梯度爆炸
所需头文件:
#include <iostream>
#include<vector>
#include<algorithm>
#include<cmath>
#include<fstream>
#include<sstream>
BP类定义:
class BP
{
private:
vector<vector<vector<double>>> w;//需要学习的权重
vector<vector<double>>b;//每层神经网络的偏置
int layers;//层数
vector<int>nl;//每层神经元数量
int m;//样本总数
int act;//激活函数种类
double c;//正则化系数
double a;//学习率
int seed;//随机种子
bool adam;//是否使用adam优化
double testp;//训练集所占比重
vector<vector<double>>za;//记录每个神经元激活值
vector<vector<double>>zz;//记录每个神经元输入值
vector<vector<double>>dz;//记录每个神经元输入的偏导
double forward(double **x, int *y, int q); //第q个样本前向传播
void back(double **x, int *y, int q); //第q个样本反向传播
double relu(double x) { return max(0.0, x); } //以下为三种激活函数以及其导函数
double drelu(double x) { return x >= 0 ? 1 : 0; }
double sigmod(double x) { return 1 / (1 + exp(-x)); }
double dsigmod(double x) { return sigmod(x)*(1 - sigmod(x)); }
double tanh(double x) { return std::tanh(x); }
double dtanh(double x) { return 1 - std::tanh(x)*std::tanh(x); }
public:
BP(int layers, int m, int *nl, double a, double c, string act = "relu", double testp = 0.7, bool adam = false, int seed = 0);
void init();
void train(double **x, int *y, int minibatch); //开始训练
double testacc(double**x, int *y); //计算测试集acc
double trainacc(double**x, int *y);//计算训练集acc
void norminput(double**x); //正则化输入
};
下面给出每个函数的定义:
构造函数,传进来层数不包括最后的输出层,所以在构造函数里加上,假设是二分类,所以最后一层只需要一个神经元。
BP::BP(int layers, int m, int *nl, double a, double c, string act, double testp, bool adam, int seed)
{
this->layers = layers + 1;
this->m = m;
for (int i = 0; i < layers; i++)
this->nl.emplace_back(nl[i]);
this->nl.emplace_back(1);
if (act == "relu")
this->act = 1;
else if (act == "tanh")
this->act = 2;
else if (act == "sigmod")
this->act = 3;
this->seed = seed;
this->a = a;
this->c = c;
this->adam = adam;
this->testp = testp;
}
初始化函数,各种申请空间和随机初始化,不解释
void BP::init()
{
srand(seed);
w = vector< vector<vector<double>>>(layers - 1);
for (int i = 0; i < layers - 1; i++)
{
w[i] = vector<vector<double>>(nl[i + 1]);
for (int j = 0; j < nl[i + 1]; j++)
{
w[i][j] = vector<double>(nl[i]);
for (int k = 0; k < nl[i]; k++)
w[i][j][k] = rand() % 1000 / (double)100000 - 0.005;
}
}
b = vector<vector<double>>(layers - 1);
for (int i = 0; i < layers - 1; i++)
{
b[i] = vector<double>(nl[i + 1]);
for (int j = 0; j < nl[i + 1]; j++)
b[i][j] = rand() % 1000 / (double)100000 - 0.005;
}
za = vector<vector<double>>(layers);
for (int i = 0; i < layers; i++)
za[i] = vector<double>(nl[i]);
zz = vector<vector<double>>(layers);
for (int i = 0; i < layers; i++)
zz[i] = vector<double>(nl[i]);
dz = vector<vector<double>>(layers);
for (int i = 0; i < layers; i++)
dz[i] = vector<double>(nl[i]);
}
单个样本前向传播,第一层就是x的输入,然后每层每个神经元依次计算输入与激活值,返回该样本的log损失误差,最后一层用sigmod计活函数
double BP::forward(double **x, int *y, int q)
{
for (int i = 0; i < nl[0]; i++)
za[0][i] = x[q][i];
for (int i = 0; i < layers - 1; i++)
{
for (int j = 0; j < nl[i + 1]; j++)
{
double z = 0;
for (int k = 0; k < nl[i]; k++)
z += w[i][j][k] * za[i][k];
z += b[i][j];
zz[i + 1][j] = z;
if (i == layers - 2)
z = sigmod(z);
else
{
switch (act)
{
case 1:z = relu(z); break;
case 2:z = tanh(z); break;
case 3:z = sigmod(z); break;
}
}
za[i + 1][j] = z;
}
}
double J = y[q] * log(za[layers - 1][0] + 1e-8) + (1 - y[q])*log(1 - za[layers - 1][0] + 1e-8);
return J;
}
单个样本反向传播求导,最后一层的导数并不是定义为a-y,而是通过损失函数对a的导与sigmod函数对z的导相乘化简而来的
void BP::back(double**x, int *y, int q)
{
dz[layers - 1][0] = za[layers - 1][0] - y[q];
for (int i = layers - 2; i > 0; i--)
{
for (int j = 0; j < nl[i]; j++)
{
double dd = 0;
for (int k = 0; k < nl[i + 1]; k++)
dd += w[i][k][j] * dz[i + 1][k];
switch (act)
{
case 1:dd *= drelu(zz[i][j]); break;
case 2:dd *= dtanh(zz[i][j]); break;
case 3:dd *= sigmod(zz[i][j]); break;
}
dz[i][j] = dd;
}
}
}
训练函数,如果minibatch大于m,就直接等于m,dnum为一轮的次数,每求完一轮,计算损失函数,与上一轮相比,相差不大于1e-6,就结束训练,如果训练200轮还没收敛,也结束训练
其中dw为损失函数对每层的w的偏导,db同理,vdw与vdb为dw与db的指数加权平均数,sdw与sdb为(dw)²与(db)²的指数加权平均数,这四个变量用来做adam优化的梯度下降
void BP::train(double **x, int *y, int minibatch)
{
vector<vector<vector<double>>> dw(layers - 1);
for (int i = 0; i < layers - 1; i++)
{
dw[i] = vector<vector<double>>(nl[i + 1]);
for (int j = 0; j < nl[i + 1]; j++)
dw[i][j] = vector<double>(nl[i]);
}
vector<vector<double>>db(layers - 1);
for (int i = 0; i < layers - 1; i++)
db[i] = vector<double>(nl[i + 1]);
vector <vector<vector<double>>>vdw(layers - 1);
for (int i = 0; i < layers - 1; i++)
{
vdw[i] = vector<vector<double>>(nl[i + 1]);
for (int j = 0; j < nl[i + 1]; j++)
vdw[i][j] = vector<double>(nl[i], 0);
}
vector<vector<double>>vdb(layers - 1);
for (int i = 0; i < layers - 1; i++)
vdb[i] = vector<double>(nl[i + 1], 0);
vector <vector<vector<double>>>sdw(layers - 1);
for (int i = 0; i < layers - 1; i++)
{
sdw[i] = vector<vector<double>>(nl[i + 1]);
for (int j = 0; j < nl[i + 1]; j++)
sdw[i][j] = vector<double>(nl[i], 0);
}
vector<vector<double>>sdb(layers - 1);
for (int i = 0; i < layers - 1; i++)
sdb[i] = vector<double>(nl[i + 1], 0);
double Jlast = 0;
double Jnow = 100000;
int t = 1;
int dnum = (int)(m*testp) % minibatch == 0 ? (m*testp) / minibatch : (m*testp) / minibatch + 1;
int anum = 0;
while (abs(Jlast - Jnow) > 1e-5)
{
Jlast = Jnow;
Jnow = 0;
int m1 = 0, m2 = min((int)(m*testp), m1 + minibatch);
for (int ci = 0; ci < dnum; ci++)
{
for (int i = 0; i < layers - 1; i++)
for (int j = 0; j < nl[i + 1]; j++)
for (int k = 0; k < nl[i]; k++)
dw[i][j][k] = 0;
for (int i = 1; i < layers; i++)
for (int j = 0; j < nl[i]; j++)
db[i - 1][j] = 0;
//cout << "epoch " << t/dnum +1 << ": " << ci + 1 << "/" << dnum << endl;
if (ci != 0)
m1 += minibatch, m2 = min((int)(m*testp), m2 + minibatch);
double J = 0;
for (int i = m1; i < m2; i++)
{
double j = forward(x, y, i);
//cout << j << endl;
J += j;
back(x, y, i);
for (int i = 0; i < layers - 1; i++)
for (int j = 0; j < nl[i + 1]; j++)
for (int k = 0; k < nl[i]; k++)
dw[i][j][k] += dz[i + 1][j] * za[i][k];
for (int i = 1; i < layers; i++)
for (int j = 0; j < nl[i]; j++)
db[i - 1][j] += dz[i][j];
}
J /= -(double)(m2 - m1);
Jnow += J;
for (int i = 0; i < layers - 1; i++)
for (int j = 0; j < nl[i + 1]; j++)
for (int k = 0; k < nl[i]; k++)
{
dw[i][j][k] = dw[i][j][k] / (double)(m2 - m1) + w[i][j][k] * c / (m2 - m1);
if (!adam)
w[i][j][k] -= a * dw[i][j][k];
else
{
vdw[i][j][k] = 0.9*vdw[i][j][k] + 0.1*dw[i][j][k];
sdw[i][j][k] = 0.999*sdw[i][j][k] + 0.001*dw[i][j][k] * dw[i][j][k];
double vdwt = vdw[i][j][k] / (1 - pow(0.9, t));
double sdwt = sdw[i][j][k] / (1 - pow(0.999, t));
w[i][j][k] -= a * vdwt / sqrt(sdwt + 1e-8);
}
}
for (int i = 1; i < layers; i++)
for (int j = 0; j < nl[i]; j++)
{
db[i - 1][j] = db[i - 1][j] / (double)(m2 - m1);
if (!adam)
b[i - 1][j] -= a * db[i - 1][j];
else
{
vdb[i - 1][j] = 0.9*vdb[i - 1][j] + 0.1*db[i - 1][j];
sdb[i - 1][j] = 0.999*sdb[i - 1][j] + 0.001*db[i - 1][j] * db[i - 1][j];
double vdbt = vdb[i - 1][j] / (1 - pow(0.9, t));
double sdbt = sdb[i - 1][j] / (1 - pow(0.999, t));
b[i - 1][j] -= a * vdbt / (sqrt(sdbt + 1e-8));
//cout << db[i - 1][j] << " " << vdbt / (sqrt(sdbt + 1e-8)) << endl;
}
}
t++;
}
//cout << Jnow << endl;
double JC = 0;
for (int i = 0; i < layers - 1; i++)
for (int j = 0; j < nl[i + 1]; j++)
for (int k = 0; k < nl[i]; k++)
JC += w[i][j][k] * w[i][j][k];
JC *= c;
JC /= 2 * (m*testp);
Jnow += JC;
//printf("%lf %lf\n", Jnow, Jlast);
if (t / dnum >= 200)
break;
}
}
两个测试函数,没啥好说的
double BP::testacc(double**x, int *y)
{
int m1 = (int)(m*testp);
int tr = 0;
for (int i = m1; i < m; i++)
{
forward(x, y, i);
if (za[layers - 1][0] >= 0.5&&y[i] == 1)
tr++;
if (za[layers - 1][0] < 0.5&&y[i] == 0)
tr++;
}
return tr / (double)(m - m1);
}
double BP::trainacc(double**x, int *y)
{
int tr = 0;
for (int i = 0; i < (int)(m*testp); i++)
{
forward(x, y, i);
if (za[layers - 1][0] >= 0.5&&y[i] == 1)
tr++;
if (za[layers - 1][0] < 0.5&&y[i] == 0)
tr++;
}
return tr / (double)(m*testp);
}
正则化输入,每个x减去均值并除以范围(标准差也可以)
void BP::norminput(double**x)
{
for (int i = 0; i < nl[0]; i++)
{
double avg = 0;
double maxx = 0;
double minn = 99999999;
for (int j = 0; j < m; j++)
{
avg += x[j][i];
maxx = max(maxx, x[j][i]);
minn = min(minn, x[j][i]);
}
avg /= m;
for (int j = 0; j < m; j++)
x[j][i] = (x[j][i] - avg) / (maxx - minn);
}
}
最后是主函数,读入文件,尝试测试不同层数的神经网络
int main() {
ifstream f;
f.open("spambase.csv");
if (!f.is_open())
{
cout << "open error" << endl;
return 0;
}
string line;
int m = 0;
int n = 0;
double **x = new double*[10000];
int *y = new int[10000];
while (getline(f, line))
{
int n1 = 0;
x[m] = new double[1000];
istringstream sin(line);
string temp;
while (getline(sin, temp, ','))
{
x[m][n1] = atof(temp.c_str());
//cout << x[m][n1] << endl;
n1++;
}
y[m] = x[m][n1 - 1] == -1 ? 0 : 1;
m++;
n = n1 - 1;
}
f.close();
int *nl = new int[11];
nl[0] = n;
nl[1] = 20;
nl[2] = 20;
nl[3] = 20;
nl[4] = 20;
nl[5] = 20;
nl[6] = 20;
for (int i = 1; i <= 6; i++)
{
BP B(i, m, nl, 0.01, 0.0001, "tanh", 0.7, true, 0);
B.init();
B.norminput(x);
B.train(x, y, 64);
double trainacc = B.trainacc(x, y);
double acc = B.testacc(x, y);
printf("%lf %lf\n", trainacc, acc);
//system("pause");
}
}