【八股文】找实习自用八股文笔记(目标检测)

1、目标检测之mAP指标的计算
1.1 计算precision和recall
网络预测出一些候选框时,即可根据预测框与ground truth框的IOU确定是否预测正确。当IOU大于某个阈值时(比如0.5),认为预测正确。
首先计算TP,TN,FN,计算方式如下:
- True Positive(TP): 一个目标框被正确检测出来, $I O U ≥ t h r e s h o l d$
- False Positive(FP): 预测框预测错误, $I O U < t h r e s h o l d$
- False Negative(FN): 目标框没有被预测出来
- True Negative(TN): 在这里不适用。
之后计算precision和recall:
- 计算P与R时,只使用预测为当前类别的预测框与当前类别的ground truth框。
1.2 绘制PR曲线
- 将当前类别的预测框按照置信度conference从大到小排序
- 然后按照顺序依次只取前n个预测框,其余忽略。
计算Precision与Recall
如下表所示: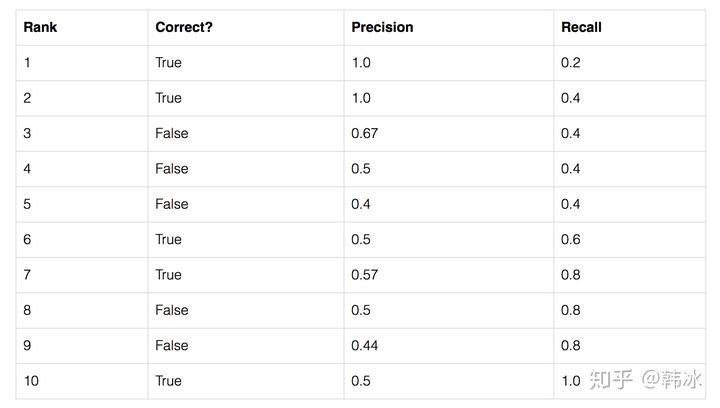
之后以R为x轴,以P为纵轴绘制PR曲线
如下图所示: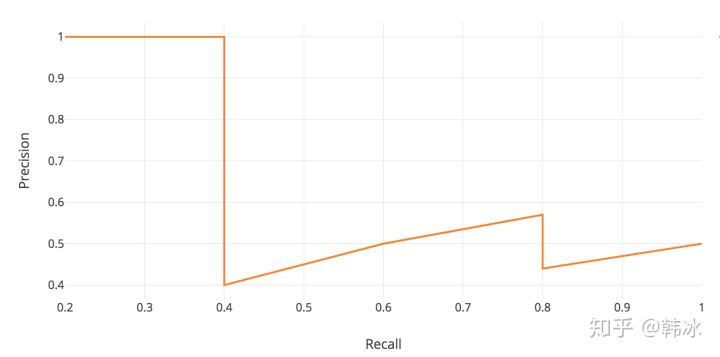
1.3 计算AP(Average Precision)与mAP(mean Average Precision)
AP就是平均精准度,对于pr曲线来说,我们使用积分来进行计算。
在实际应用中,要先对PR曲线进行平滑处理。即对PR曲线上的每个点,Precision的值取该点右侧最大的Precision的值。即:$P_{\text {smooth }}(r)=\max _{r^{\prime}>=r} P\left(r^{\prime}\right)$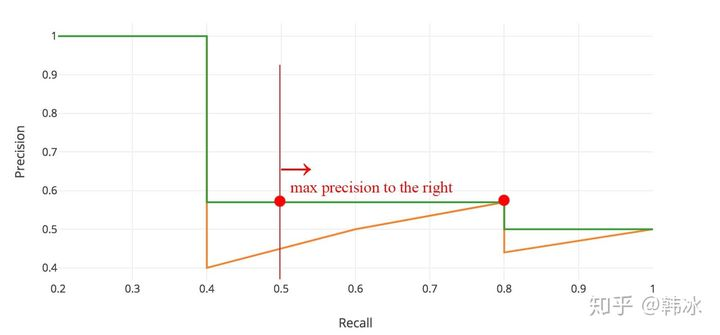
最终计算平滑后的PR曲线下面积为AP值:
而mAP值为在不同类下计算AP值后的均值:
1.4 参考
https://blog.csdn.net/u010712012/article/details/85108738
https://blog.csdn.net/chris_xy/article/details/103036756
https://zhuanlan.zhihu.com/p/88896868
2、目标检测之RCNN
2.1 算法流程
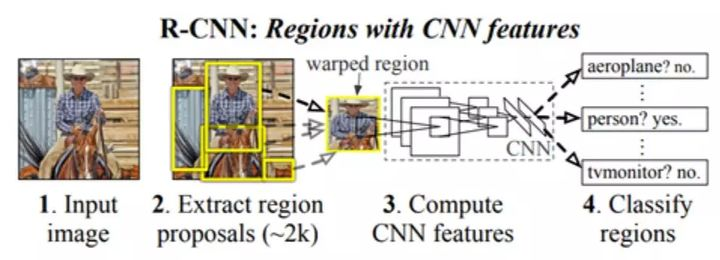
1、输入测试图片
2、利用selective search算法从图像中提取2k左右个region proposals(备选区域)
3、将每一个region proposals缩放成227x227的大小并输入CNN网络,在最后一层全连接输出图像特征(特征提取)
4、把每个region proposal的CNN特征输入到SVM进行分类处理
5、对SVM分类好的region proposal进行边框回归处理,使得预测框和真实框更加吻合(边框回归)
2.2 Selective Search
--------------------------------
利用切分方法得到候选的区域集合R = {r1,r2,…,rn}
初始化相似集合S = ϕ
foreach 遍历邻居区域对(ri,rj) do
计算相似度s(ri,rj)
S = S ∪ s(ri,rj)
while S not=ϕ do
从S中得到最大的相似度s(ri,rj)=max(S)
合并对应的区域rt = ri ∪ rj
移除ri对应的所有相似度:S = S\s(ri,r*)
移除rj对应的所有相似度:S = S\s(r*,rj)
计算rt对应的相似度集合St
S = S ∪ St
R = R ∪ rt
其中第一步生成候选区域R所需算法:
基于图的图像分割(Graph-Based Image Segmentation)
https://blog.csdn.net/guoyunfei20/article/details/78727972
2.2.1 评价相似度
两块区域为$r_i,r_j$
1、颜色相似度
使用L1-norm归一化获取图像每个颜色通道的25 bins的直方图,这样每个区域都可以得到一个75维的向量$\{c_i^1,\dots, c_i^n \}$,区域之间颜色相似度通过下面的公式计算:
每一个颜色通道的直方图累加和为1.0,三个通道的累加和就为3.0,如果区域ci和区域cj直方图完全一样,则此时颜色相似度最大为3.0,如果不一样,由于累加取两个区域bin的最小值进行累加,当直方图差距越大,累加的和就会越小,即颜色相似度越小。
合并后新相似度为:
2、纹理相似度
每个颜色通道的8个不同方向计算方差σ=1的高斯微分(Gaussian Derivative),使用L1-norm归一化获取图像每个颜色通道的每个方向的10 bins的直方图,这样就可以获取到一个240(10x8x3)维的向量$T_i=\{t_i^1\dots t_i^n\}$,区域之间纹理相似度计算方式和颜色相似度计算方式类似,合并之后新区域的纹理特征计算方式和颜色特征计算相同:
3、优先合并小的区域(小的区域权重更大)
否则,容易使得合并后的区域不断吞并周围的区域。
4、区域的合适度距离
这里定义区域的合适度距离主要是为了衡量两个区域是否更加“吻合”,其指标是合并后的区域的Bounding Box(能够框住区域的最小矩形BBij)越小,其吻合度越高,即相似度越接近1。
合并
2.3 CNN结构与类别预测
Alexnet
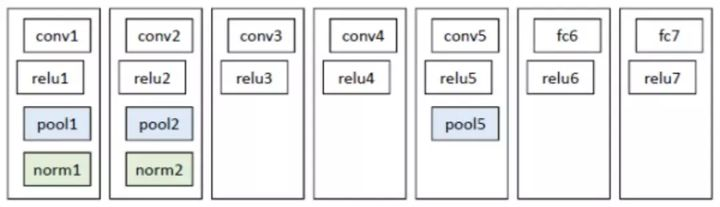
- 因为R-CNN的网络结构中存在有全连接层(fc),需要输入图像的尺寸保持一致,所以必须resize成227*227。
- 一个region proposal经过CNN网络输出4096维的特征
- 对每一类使用SVM进行二分类,判断是否属于此类。
2.4 边框回归
虽然已经使用了selective search来最大限度地提取目标的候选框,但有些候选框与真实框依旧有很大差距,因此使用一个线性方程来实现位置的精确定位。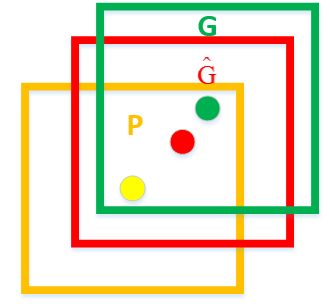
如上图,黄色框口P表示建议框Region Proposal,绿色窗口G表示实际框Ground Truth,红色窗口表示Region Proposal进行回归后的预测窗口,现在的目标是找到P到$\hat{G}$的线性变换,使得与G越相近。
若 $G=\left(G_{x}, G_{y}, G_{w}, G_{h}\right)$ ,四个元素的位移为:($\Delta_{x}, \Delta_{y}, \Delta_{w}, \Delta_{h}$), RCNN希望网络预测四个变量($d_{x}(P)$, $d_{y}(P)$, $d_{w}(P)$, $d_{h}(P)$ ),来拟合四个元素的位移。最终与原坐标相加来拟合G。建立方程组:
每一个 $d_{*}(P)$ 都是AlexNet的Pool5层特征$\phi_5(P)$ 的线性函数 $d_{*}(P)=w_{*}^{T} \phi_{5}(P)$,其中 $w$ 为需要学习的参数。则损失函数为:
其中:
2.5 NMS(非极大抑制)
假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
代码:
def NMS(dects,threshhold):
"""
detcs:二维数组(n_samples,5)
5列:x1,y1,x2,y2,score
threshhold: IOU阈值
"""
x1=dects[:,0]
y1=dects[:,1]
x2=dects[:,2]
y2=dects[:,3]
score=dects[:,4]
ndects=dects.shape[0]#box的数量
area=(x2-x1+1)*(y2-y1+1)
order=score.argsort()[::-1] #score从大到小排列的indexs,一维数组
keep=[] #保存符合条件的index
suppressed=np.array([0]*ndects) #初始化为0,若大于threshhold,变为1,表示被抑制
for _i in range(ndects):
i=order[_i] #从得分最高的开始遍历
if suppressed[i]==1:
continue
keep.append(i)
for _j in range(i+1,ndects):
j=order[_j]
if suppressed[j]==1: #若已经被抑制,跳过
continue
xx1=np.max(x1[i],x1[j])#求两个box的交集面积interface
yy1=np.max(y1[i],y1j])
xx2=np.min(x2[i],x2[j])
yy2=np.min(y2[i],y2[j])
w=np.max(0,xx2-xx1+1)
h=np.max(0,yy2-yy1+1)
interface=w*h
overlap=interface/(area[i]+area[j]-interface) #计算IOU(交/并)
if overlap>=threshhold:#IOU若大于阈值,则抑制
suppressed[j]=1
return keep
2.6 参考
https://zhuanlan.zhihu.com/p/23006190
https://zhuanlan.zhihu.com/p/53829435
https://blog.csdn.net/qq_43243022/article/details/88895057
3、目标检测之Fast RCNN与Faster RCNN
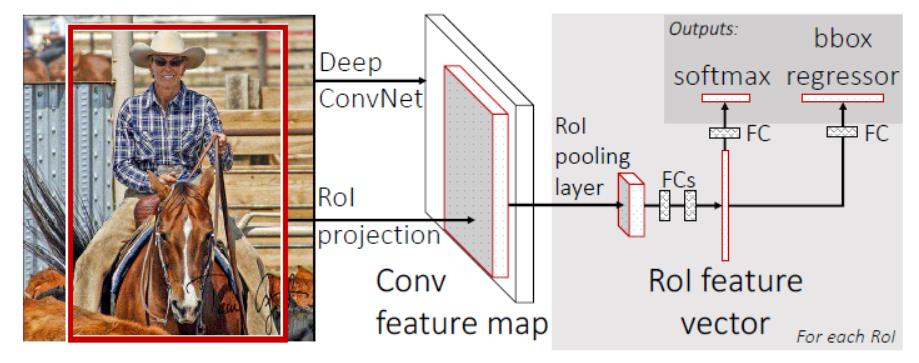
3.1 Fast R-CNN
- RCNN对每个region都进行CNN提取特征,由于region重叠部分较多,使CNN对相同区域提取多次,耗费时间。
- 并且RCNN提取region特征之前需要resize,破坏图中内容的结构,影响效果。
所以Fast R-CNN诞生了。
3.1.1 流程
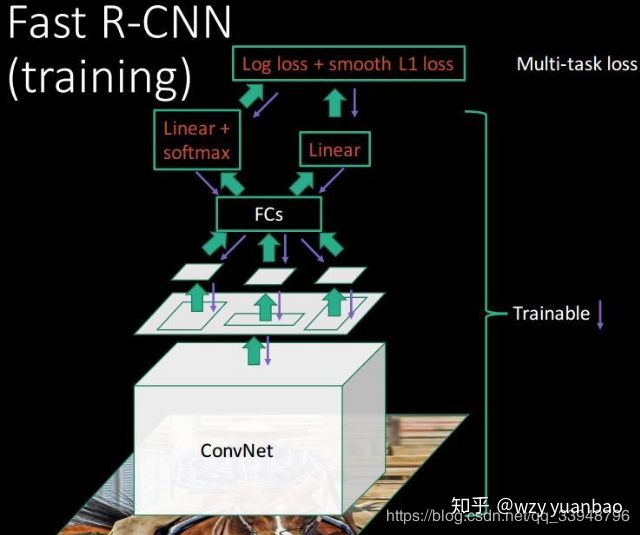
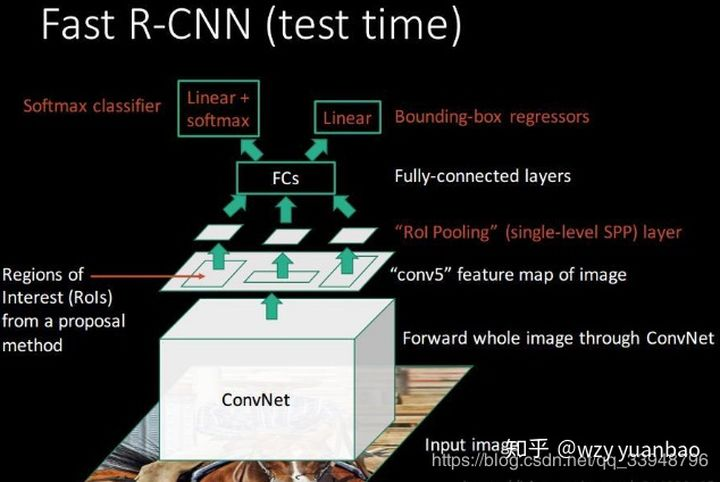
如图,Fast R-CNN将整张图片resize送入神经网络(RCNN是对每个region进行resize),在最后一层再加入候选框信息(这些候选框还是经过Selective Search提取,再将在原图中的位置映射到最后一层特征图上),这样CNN提取特征只需对整张图做一次提取即可。
使用ROI pooling layer对最后一层特征图中每个region的对应的区域进行pooling,产生固定大小的输出,再送进FC层。
FC层的输出两部分,使用了多任务损失函数(multi-task loss)。
3.1.2 ROI pooling layer
作用:对任意大小的输入产生固定的输出
3.1.2.1 输入
提取特征的网络的最后一个特征图层;
一个表示图片中所有ROI的N*5的矩阵,其中N表示ROI(region of interest)的数目。第一列表示图像index,其余四列表示坐标(x,y,h,w)。坐标的参考系不是针对feature map的。其中x,y表示RoI的左上角在整个图片中的坐标。
3.1.2.2 输出
输出为,与ROI同数量的vector,vector大小为channel*w*h。channel为最后一层feature map的channel数。w,h为约定好的固定大小的输出。
3.1.2.3 计算过程
- 1、根据输入image,将ROI坐标映射到feature map对应位置
- 将映射后的区域划分为相同大小的区域,区域数量与约定好的输出数量相同。
- 对每个区域进行max pooling操作
具体计算过程如下动图所示(假设输出w,h为2*2):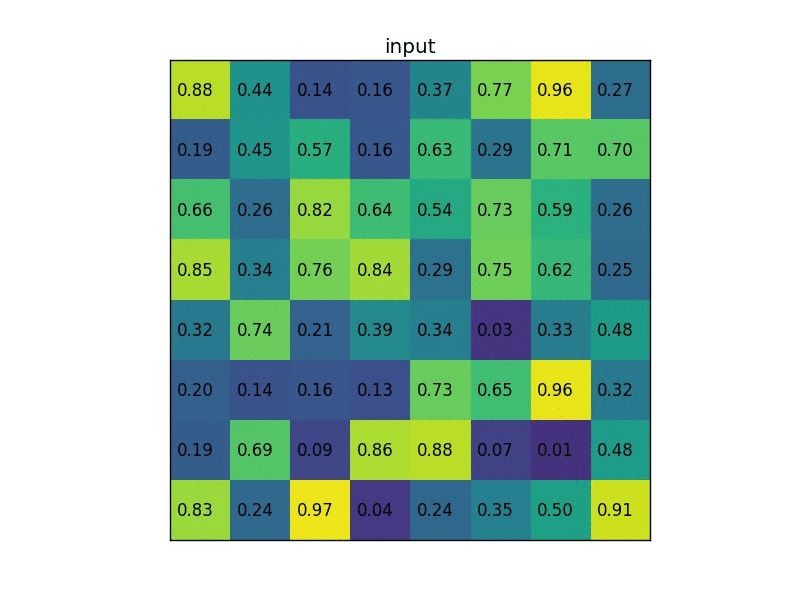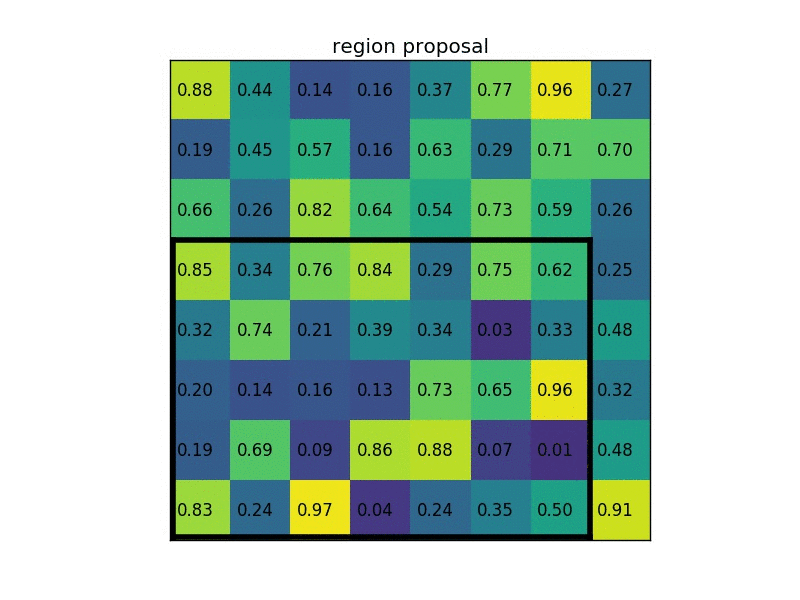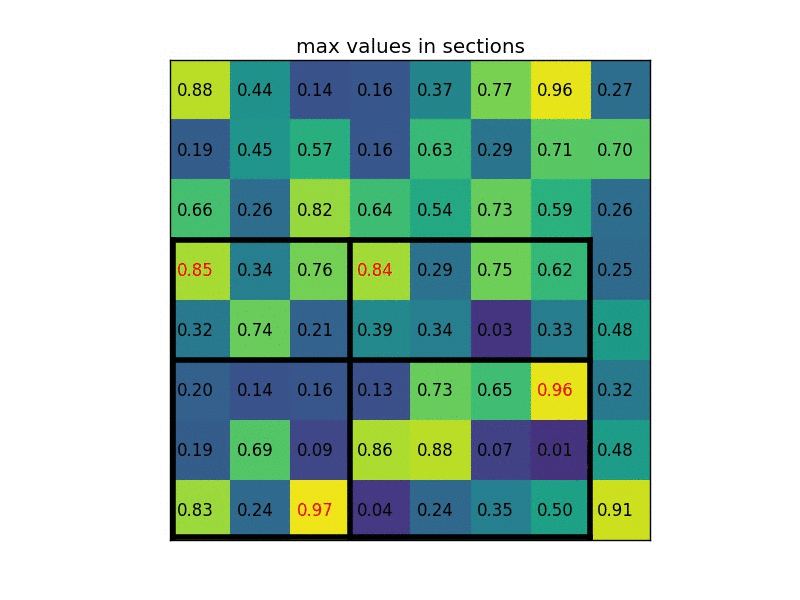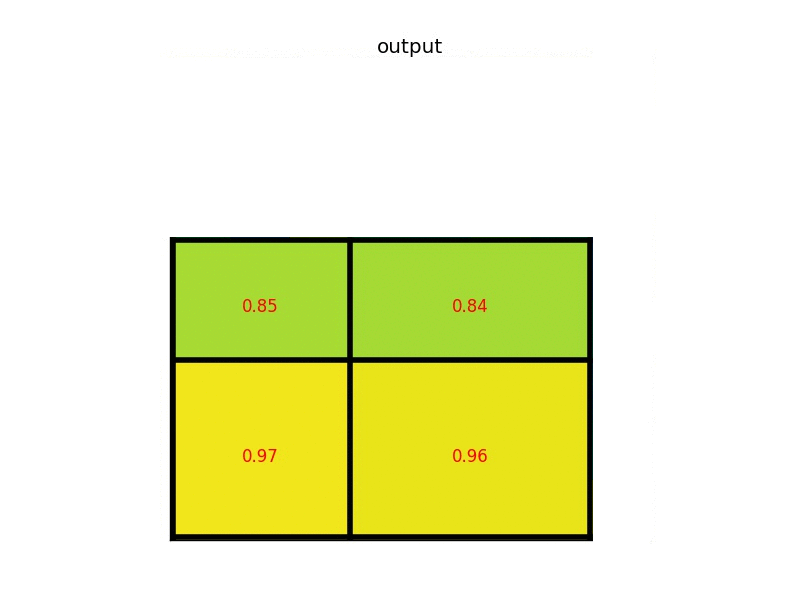
3.1.3 损失函数
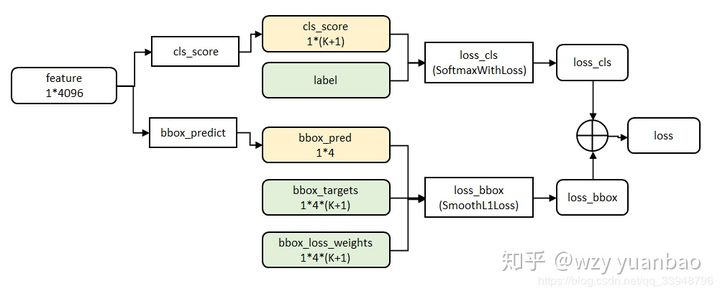
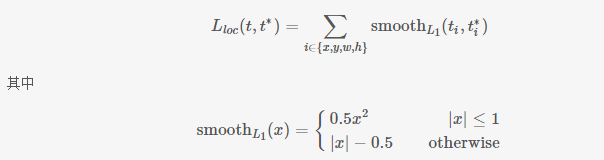
smooth的图像为: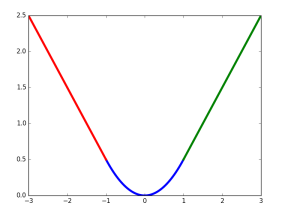
3.2 Faster R-CNN
Fast R-CNN与R-CNN一样需要预先Selective Search,该过程速度较慢。
所以Faster R-CNN将region提取的过程融入进网络里。
3.2.1 流程
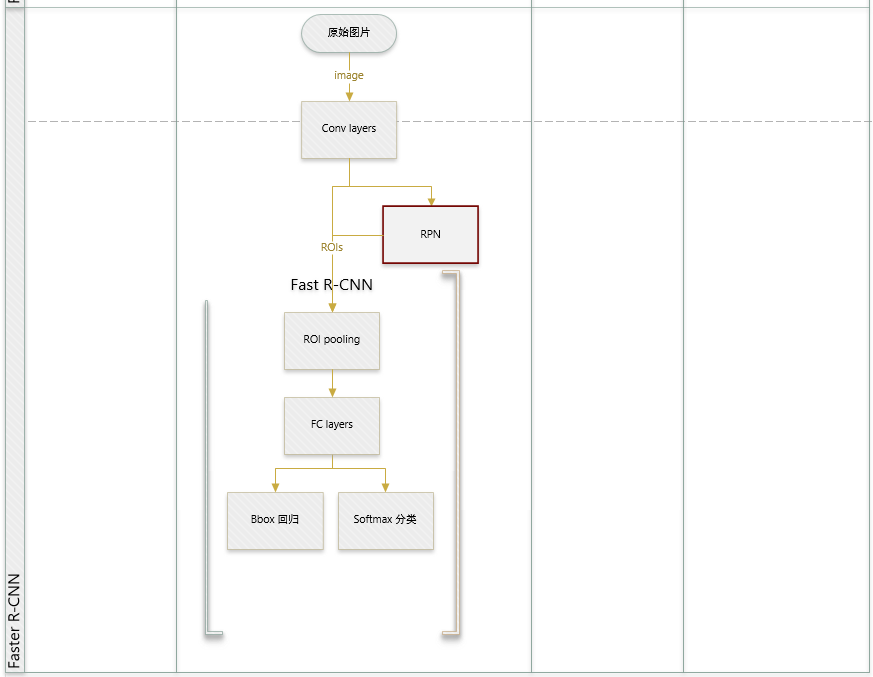
从图中可以看出,该网络结构大部分与Fast R-CNN相同,唯一不同的是最后一层卷积的输出feature map输入给了RPN网络来生成region位置,并使用生成的位置和最后一层feature map作为ROI pooling layer的输入。
3.2.2 区域生成网络 ( Region Proposal Networks )
RPN可以帮我们找出可能包含物体的那些区域
RPN使用固定大小的anchor,这些anchor将会均匀地放置在整个原始图像中。不同于原来我们要检测物体在哪里,我们现在利用anchor将问题转换为另外两部分:
- 某个框内是否含有物体
- 某个框是否框的准,如果框的不准我们要如何调整框
3.2.2.1 anchors
如果直接学习物体边框$(x_{min},x_{max},y_{min},y_{max})$是困难的:
- 边框数量不定,网络很难输出变长的数据
- 物体是不同大小有不同的宽高比,那训练一个效果很好的检测模型将会是非常复杂的
- 会存在一些无效的预测,比如$x_{max}<x_{min}$时
所以RPN使用anchors的方法。RPN在feature map对应的原图位置上,以每个点为中心上使用9个anchors:
- 三种面积{128,256,512}
- 三种比例{1:1,1:2,2:1}
如下图所示: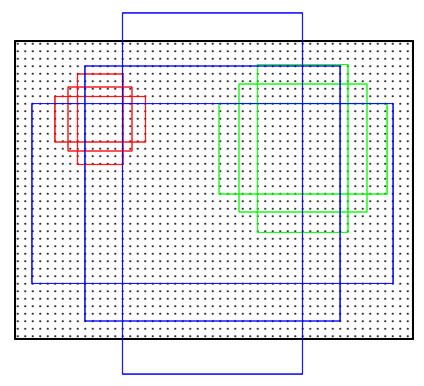
最终将学习每个anchor中是否有东西,以及anchor坐标的偏移(学习偏移比直接学习边框位置简单)。
anchor位置:$(x_{center},y_{center},width,height)$
学习的偏移:$(\Delta x_{center},\Delta y_{center},\Delta width,\Delta height)$
修正过程:(g为ground-truth,a为anchor)
3.2.2.2 输入与输出
我们使用第一部分返回的feature map进行输入,以全卷积的方式实现RPN。我们首先使用一个3*3*512的卷积层,然后使用两个并行的1*1的卷积内核,其中两个并行卷积层的通道数取决于每个点的Anchor数量(k个)。
如图所示: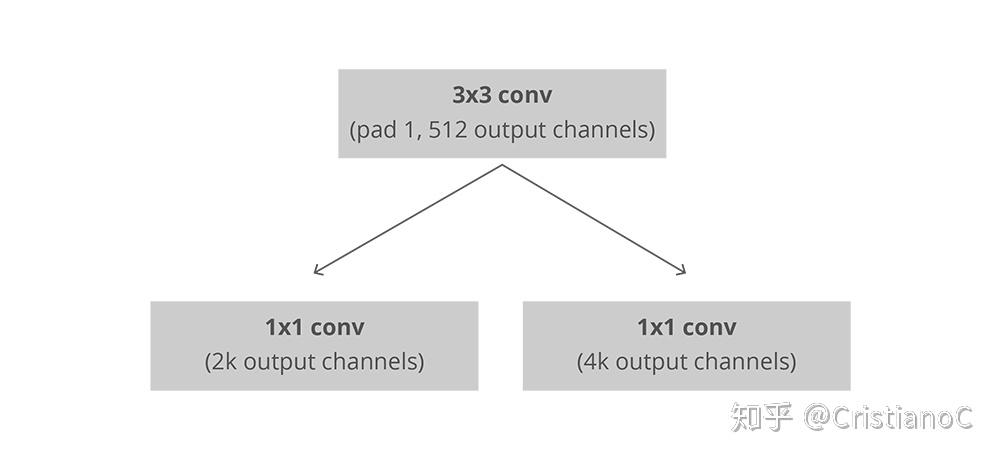
- 第一部分为分类层(左侧),我们为每个Anchor输出2个预测值:背景得分以及前景得分(实际含有物体)。
- 第二部分为回归层,输出4个预测值:为anchor的偏移值$(\Delta x_{center},\Delta y_{center},\Delta width,\Delta height)$
卷积过程如下图所示: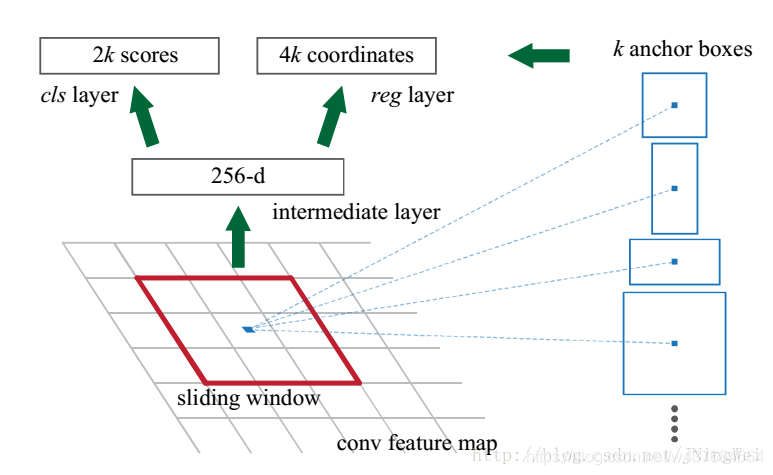
- 第一个33卷积相当于将每个3\3的滑动窗口转化为一个1维向量代表该滑动窗口内的特征。该滑动窗口的感受野包括了9个以该点位中心的anchor的面积。该卷积需要1*1 padding,即边缘部分的滑动窗口也需要计算。
- 之后的两个1*1卷积相当于FC层,相当于将每个滑动窗口的特征向量进行计算,得到该滑动窗口内的9个anchor的输出值。
- 两次卷积的输出的w,h不变,代表该这些滑动窗口的计算结果。
3.2.2.3 RPN网络的训练以及损失函数
监督标签
与ground-truth的IoU大于0.7的Anchor视为前景(如果没有就找一个与ground-truth的IoU最大的anchor),而与真实物体IoU小于0.3的视为背景。而IoU处于两个阈值中间的则忽略。
- 每个ground-turth可能有多个anchor对应
- 打上正标签的anchor,将对应的groud-truth位置作为回归学习的目标
平衡正负样本
由于图中大部分区域都是背景,所以负标签较多。则每次使用mini-batch采样训练(一般为256)。每次采样128正样本anchor,并采样同数量负样本。(若正样本不足128,则采样同数量负样本)。
损失函数
- 对于分类损失,通过二分类交叉熵进行计算
- 对应回归损失,只会针对那些正样本进行回归,具体来说就是对偏移进行回归$(\Delta x_{center},\Delta y_{center},\Delta width,\Delta height)$。损失函数使用Smooth L1损失。
3.2.2.4 RPN的输出处理
- 取所有输出为正的region的得分前M个region作为输出。
- clip限定超出图像边界的前景anchor作为图像边界
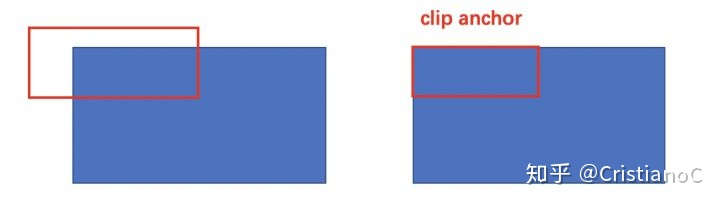
- 忽略掉长或者宽太小的建议框
- 进行NMS
- 最后重新再按得分排序,取得分前N个框
3.2.3 Faster-RCNN整体训练过程
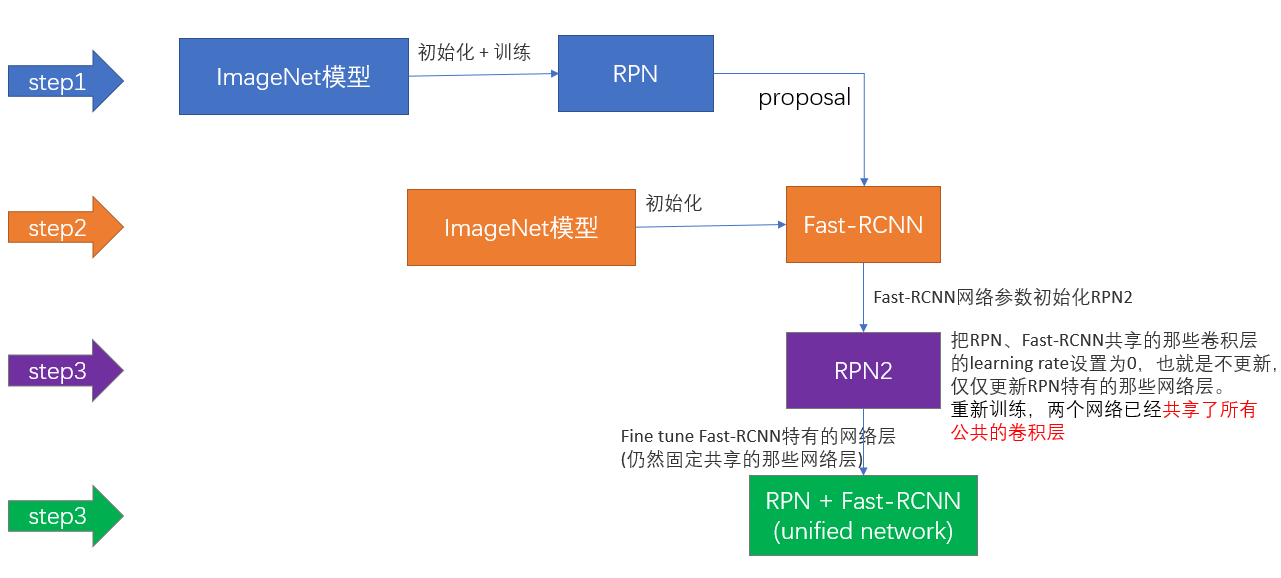
第一步:用ImageNet模型初始化,独立训练一个RPN网络;
第二步:仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络,至此,两个网络每一层的参数完全不共享;
第三步:使用第二步的Fast-RCNN网络参数初始化一个新的RPN网络,但是把RPN、Fast-RCNN共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,此时,两个网络已经共享了所有公共的卷积层;
第四步:仍然固定共享的那些网络层,把Fast-RCNN特有的网络层也加入进来,形成一个unified network,继续训练,fine tune Fast-RCNN特有的网络层,此时,该网络已经实现我们设想的目标,即网络内部预测proposal并实现检测的功能。
3.3 参考
https://zhuanlan.zhihu.com/p/24780395
https://zhuanlan.zhihu.com/p/24916624
https://zhuanlan.zhihu.com/p/123962549
https://blog.csdn.net/w437684664/article/details/104238521
https://www.cnblogs.com/jiangnanyanyuchen/p/9433791.html
4、目标检测之YOLO系列v1v2v3
4.1 YOLO v1
4.1.1 优点
- 1、YOLO是一阶段的方法,速度比RCNN系列更快。
- 2、YOLO在CNN中计算了图像中的全部特征,而RCNN在分类时系列只看到了局部特征。即YOLO使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
4.1.2 流程
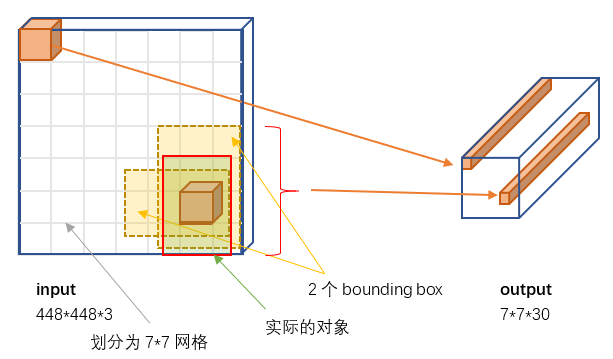
- 1、Resize成448*448,图片分割得到7*7网格(cell)
- 2、CNN提取特征和预测:卷积提取特征。全链接部分负责预测。
- 3、过滤bbox(通过nms)
4.1.3 输入与输出
图片缩放到448*448的大小,因为网络结构最后欧全连接层
4.1.4 输出
YOLO将输入图像分成SxS(S=7)个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。

4.1.4.1 bounding box
为每个格子预先设置B个bounding box(B=2)。则每个格子的输出要包含B个bounding box的信息,包括x,y,w,h,和confidence。
其中x,y代表在该格子内的相对偏移,取值[0,1]。w,h取值可以大于1。
bounding box的置信度Label计算方式为:
- $\operatorname{Pr}(\text { Object })$代表该bounding box中是否包含物体。若包含物体,则P(object) = 1;否则P(object) = 0。
- $I O U_{\text {pred }}^{\text {truth }}$为预测的bounding box与真实bounding box的接近程度。
- Label中的IOU是在训练阶段通过ground truth计算的。在测试时无法计算,也无需计算。
4.1.4.2 输出结构
YOLO原来需要检测图片中的20中物体,所以要进行20类分类,输出结构如图所示: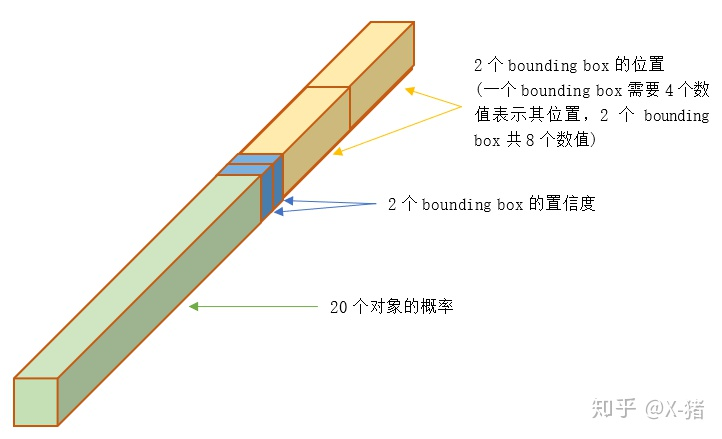
所以输出是一个 7*7*30 的张量
4.1.5 网络结构
YOLO检测网络包括24个卷积层和2个全连接层,如下图所示。
4.1.6 损失函数

最上部分为坐标误差,中间部分为IOU误差,最后部分为分类误差
其中w与h需要先开根号再使用均方误差,原因如下:
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。在下图中small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。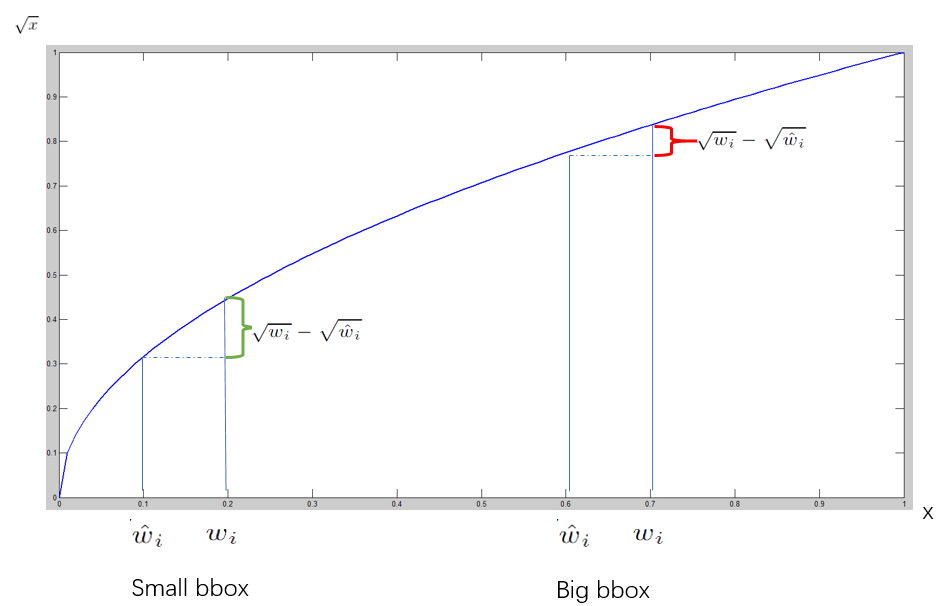
4.2 YOLO v2
4.2.1 网络结构
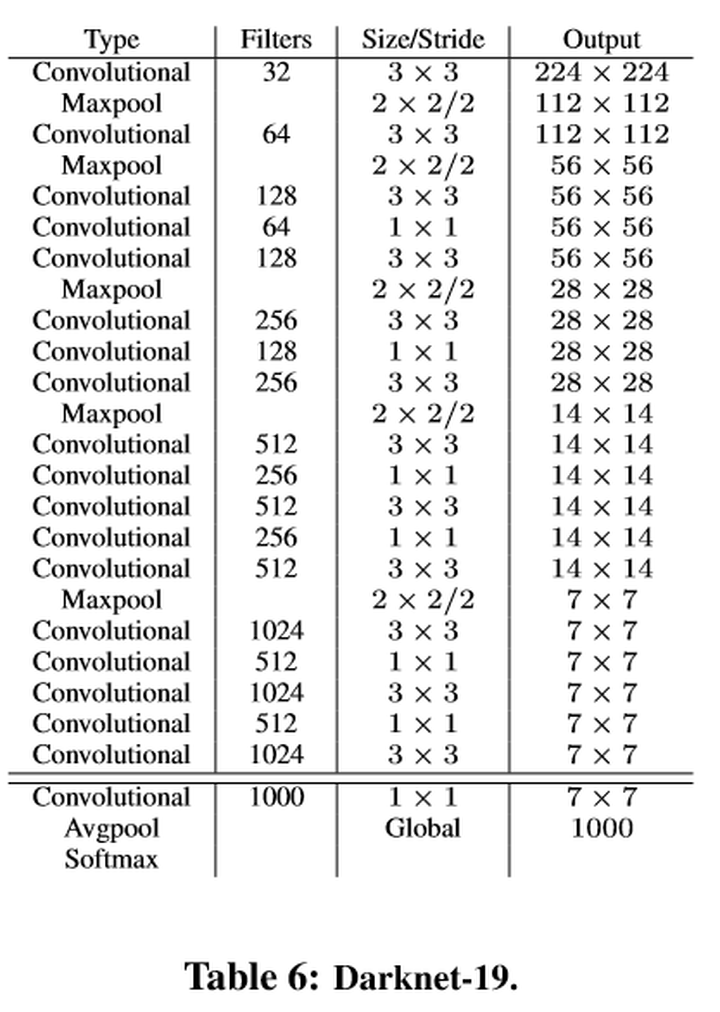
4.2.2 一系列改进
4.2.2.1 引入BN
在每一个卷积层后添加batch normalization,极大的改善了收敛速度同时减少了对其它regularization方法的依赖(舍弃了dropout依然没有过拟合),使得mAP获得了2%的提升。
4.2.2.2 高分辨率预训练
YOLOv1在训练时先使用224x224的图片输入来预训练自己的特征提取网络,再使用448x448的数据集进行finetune。这说明网络需要重新学习识别大尺度(448)的图片以及学习进行其上的目标检测工作。
YOLOv2首先修改预训练分类网络的分辨率为448*448,在ImageNet数据集上训练10轮(10 epochs)。这个过程让网络有足够的时间调整filter去适应高分辨率的输入。然后fine tune为检测网络。mAP获得了4%的提升。
4.2.2.3 使用anchor box
YOLO(v1)使用全连接层数据进行bounding box预测(要把14701的全链接层reshape为77*30的最终特征),这会丢失较多的空间信息定位不准。
- 移除全连接层
- 去掉最后的池化层确保输出的卷积特征图有更高的分辨率。
- 缩减网络,让图片输入分辨率为416 * 416,目的是让后面产生的卷积特征图宽高都为奇数
- 使用卷积层降采样(factor 为32),最终得到13 * 13的卷积特征图(416/32=13)。
- 把预测类别的机制从空间位置(cell)中解耦,由9个anchor box同时预测类别和坐标。
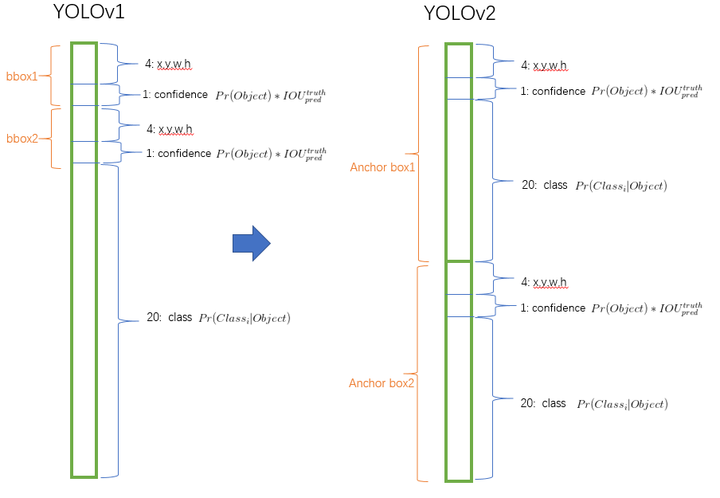
共会预测13 * 13 * 9 = 1521个boxes,而之前的网络仅仅预测7 * 7 * 2 = 98个boxes。
4.2.2.4 Kmeans寻找预设anchors形状
选择了更好的、更有代表性的先验boxes维度,那么网络就应该更容易学到准确的预测位置。
使用K-means聚类方法,通过对数据集中的ground truth box做聚类,找到ground truth box的统计规律。
若使用欧式距离,则大boxes比小boxes产生更多error。使用以下距离:
最终选择k=5。
4.2.2.5 预测相对位置
由于借鉴了Faster-RCNN的anchor,但使用Faster-RCNN的位置回归计算方式不容易收敛,因为
这个公式没有任何限制,无论在什么位置进行预测,任何anchor boxes可以在图像中任意一点。
所以要预测相对位置,网络在特征图(13 *13 )的每个cell上预测5个bounding boxes,每一个bounding box预测5个坐标值:tx,ty,tw,th,to。如果这个cell距离图像左上角的边距为(cx,cy)以及该cell对应的box的长和宽分别为(pw,ph),那么对应的box为:
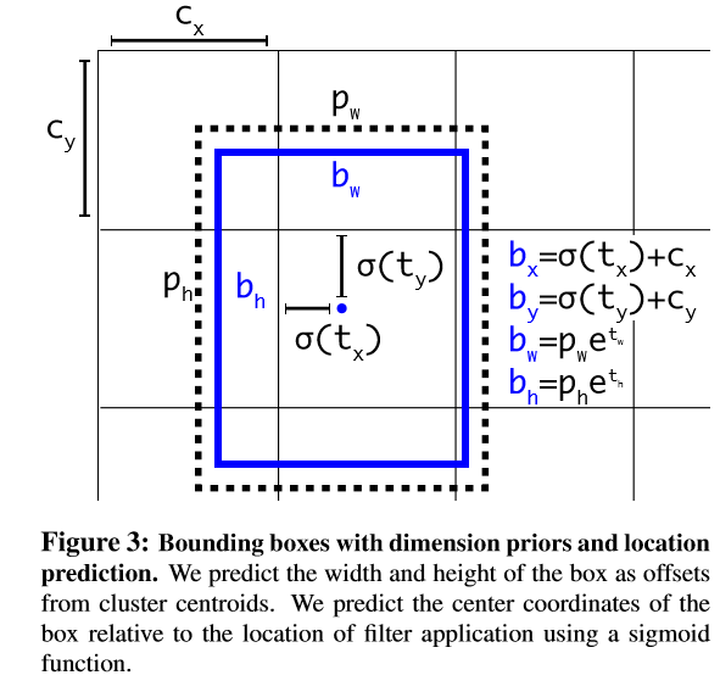
4.2.2.6 细粒度特征
在不同层次的特征图上产生区域建议以获得多尺度的适应性。
YOLO v2使用passthrough layer,将倒数第二层特征图(26*26)叠加相邻特征到不同通道,把26 * 26 * 512的特征图叠加成13 * 13 * 2048的特征图,与原生的深层特征图相连接。
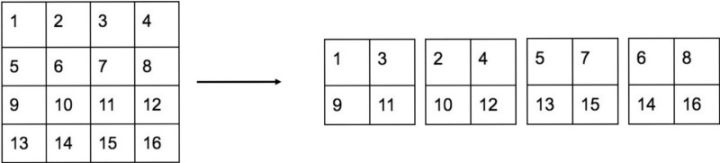
4.2.2.7 多尺度训练
由于网络取消了全连接层,所以可以使用多种分辨率的输入图片进行训练。
4.2.3 损失函数

- 第一行计算的是当前anchor box内无物体时,希望预测结果为0。(也就是背景置信度误差)
- 第二行为预测结果与预设anchor box形状的误差,让网络从启动后快速学到anchor的形状的过程,只在前12800次迭代正起作用。
- 第三行为坐标损失预测结果与ground truth的误差
- 第四行为置信度损失,也就是每个anchor box的conferen的损失
- 第五行为分类损失,均方误差与YOLO v1一样。
- 其中第2行需要变为$(2-w_i*h_i)*(prior_k^r-b_{ijk}^r)$,第三行同理。原因与YOLO v1相同,大目标对wh约束不强,小目标更严格。而YOLO v1中的开根号方式作者认为没用。所以改用这样的形式。
4.3 YOLO v3
4.3.1 网络结构
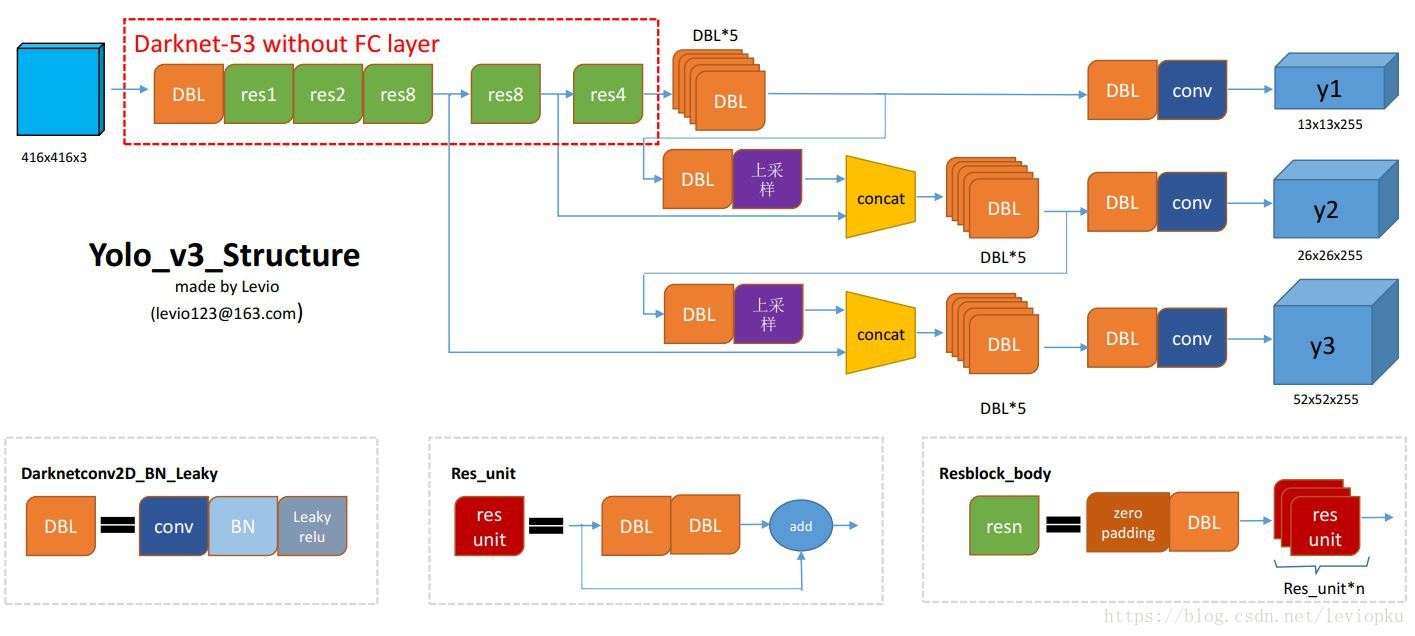

此结构主要由75个卷基层构成,没有池化层和全连接层,张量的尺寸变换是通过改变卷积核的步长来实现的。
yolo_v2中对于前向过程中张量尺寸变换,都是通过 最大池化来进行,一共有5次。而v3是通过卷积核 增大步长来进行,也是5次。
网络预测部分类似FPN结构: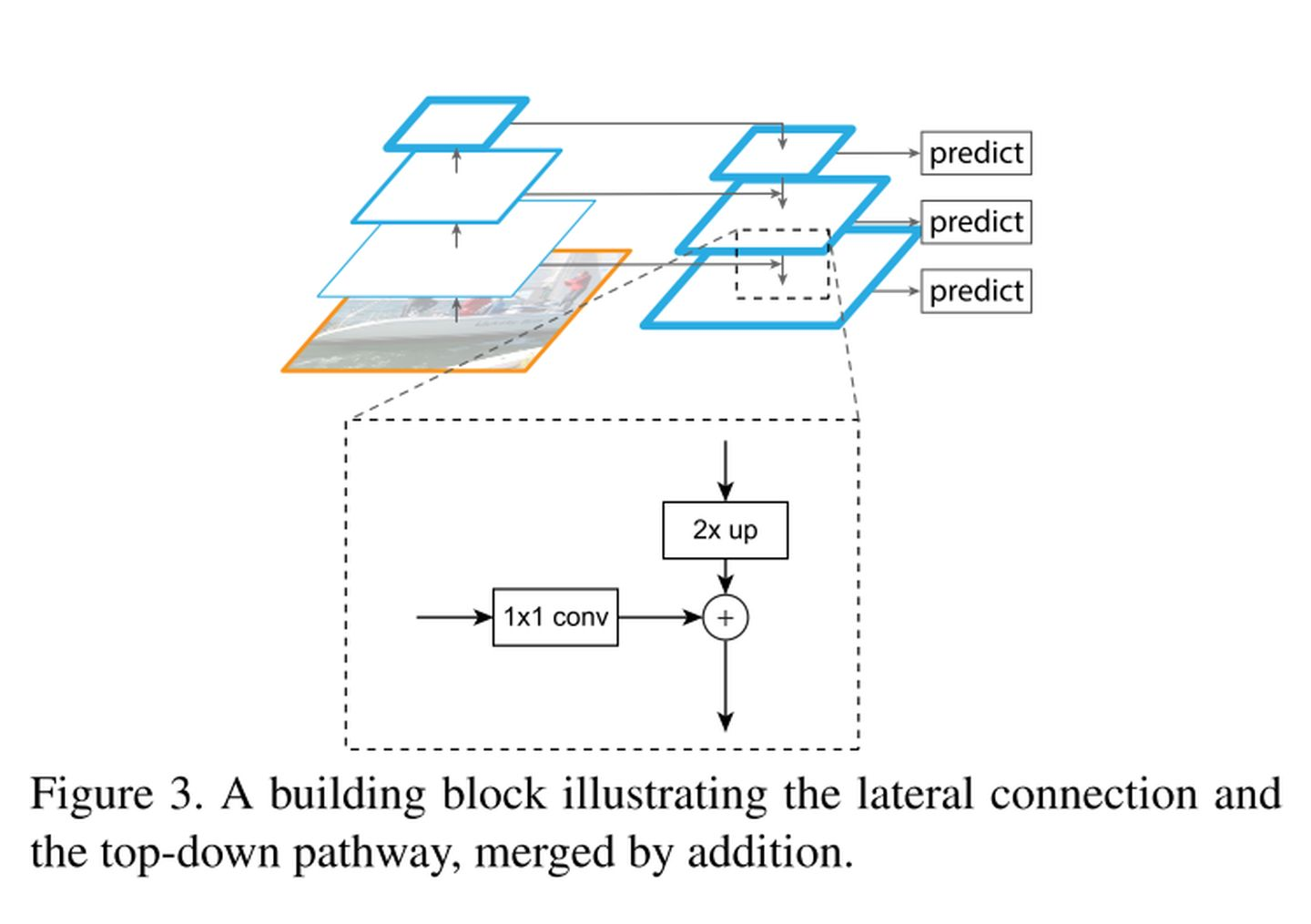
4.3.2 输出
每个输出都为255维向量,规模分别为13,26,52为在不同尺度上进行预测的结果。输出使用3个bounding box,COCO数据集共80类,每个box有(x,y,w,h,conference)信息,所以(80+5)*3=255。
与YOLOv2一样,YOLOv3也是在feature map上对每个位置进行bbox预测。预测相对当前grid的相对值,分别是(tx,ty,tw,th)。最终的预测bbox为:bx,by,bw,bh,这是在image的bbox。(唯一不同是YOLOv2用5个box)
4.3.3 替换softmax层:对应多重label分类
Softmax层被替换为一个1x1的卷积层+logistic激活函数的结构。使用softmax层的时候其实已经假设每个输出仅对应某一个单个的class,但是在某些class存在重叠情中,使用softmax就不能使网络对数据进行很好的拟合。
4.3.4 损失函数
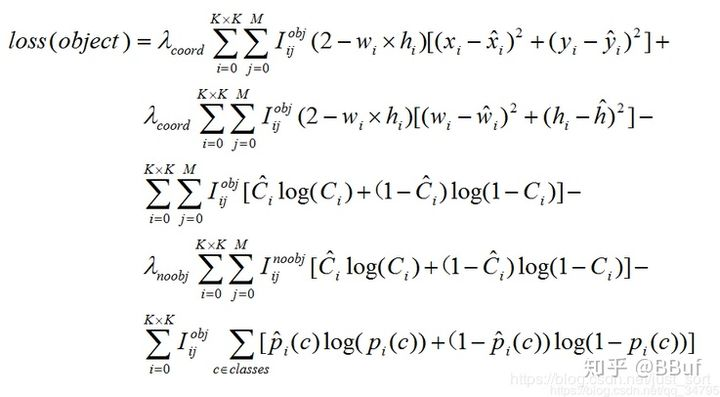
- 上面两行为bounding box预测误差,与YOLO v2相同。
- 第三行第四行为bounding box 的conference的二元交叉熵误差,第三行为有物体情况,第四行为无物体情况。由于图片中大部分区域无物体,所以无物体情况乘衰减系数$\lambda_{noobj}$,比如0.5
- 第五行为分类误差,使用二元交叉熵。
4.4 参考
https://zhuanlan.zhihu.com/p/46691043
https://zhuanlan.zhihu.com/p/24916786
https://zhuanlan.zhihu.com/p/25236464/
https://blog.csdn.net/c20081052/article/details/80236015
https://zhuanlan.zhihu.com/p/25167153
https://blog.csdn.net/leviopku/article/details/82660381
https://zhuanlan.zhihu.com/p/40332004
https://blog.csdn.net/just_sort/article/details/103232484
https://zhuanlan.zhihu.com/p/142408168